GPTBot 막으면 ChatGPT 검색에서 조용히 밀릴까? 수억 회 봇로그로 본 답

GPTBot 막으면 ChatGPT 검색에서 조용히 밀릴까?
CRAWLER POLICY
수억 회 봇로그로 본 AI crawler 정책 리스크
Search OS / AI Render · Bot Log · GEO Operations
△ Search OS
GPTBot 막으면 ChatGPT 검색에서 조용히 밀릴까? 수억 회 봇로그로 본 답
AI 검색 정책을 정하다 보면 마케팅팀과 보안팀이 같은 질문 앞에서 멈춥니다.
"AI 검색에는 나오고 싶은데, 우리 콘텐츠가 모델 학습에 쓰이는 건 막고 싶습니다. GPTBot을 막아도 괜찮을까요?"
Search OS가 고객사 운영에서 확인한 흐름은 단순했습니다. GPTBot을 막는다고 ChatGPT 검색에서 바로 사라지지는 않습니다. 시간이 지나며 인용 빈도는 약해질 수 있습니다. 이 차이를 모르면 운영이 꼬입니다. Search OS는 실제 고객사 사이트에서 수억 회 규모의 봇로그를 다뤄왔고, 자동화 페이지와 AI Render가 적용된 대규모 페이지를 운영하면서 여러 AI crawler 접근 패턴을 봤습니다. 그 안에서 반복해서 보인 흐름이 있습니다. GPTBot을 차단해도 기존에 잡혀 있던 ChatGPT 답변과 인용은 한동안 남았습니다. 재수집과 재평가가 반복되면서 인용 횟수와 답변 내 등장 빈도는 점점 약해졌습니다. 그래서 질문을 "막을까, 열어둘까"로만 잡으면 금방 어긋납니다. 어떤 bot을 왜 막는지도 모른 채, 검색 노출과 학습 차단을 한 줄의 robots.txt 정책으로 같이 처리하는 순간 진짜 리스크가 생깁니다.
GPTBot은 ChatGPT 검색 bot이 아닙니다
OpenAI는 crawler를 용도별로 나눕니다. 공식 문서 기준으로 OAI-SearchBot, GPTBot, ChatGPT-User는 같은 의미가 아닙니다.
구분 | 주된 용도 | 마케터가 봐야 할 의미 |
|---|---|---|
| ChatGPT 검색 기능에서 웹사이트를 검색 결과로 노출하는 데 사용 | ChatGPT 검색 답변에 나오고 싶다면 관리해야 하는 bot |
| OpenAI foundation model 학습에 쓰일 수 있는 콘텐츠 수집 | 학습 사용을 막고 싶은 팀이 주로 차단을 검토하는 bot |
| 사용자가 ChatGPT에서 특정 작업을 요청할 때 발생하는 user-triggered 접근 | 자동 크롤링과 다르게 봐야 하는 접근 |
운영자가 챙길 대목은 분명합니다. OAI-SearchBot은 허용하고 GPTBot은 차단하는 식의 분리 운영이 가능합니다. 즉, "ChatGPT 검색에는 나오고 싶지만, 학습에는 쓰이고 싶지 않다"는 정책 자체는 기술적으로 구분해 표현합니다.
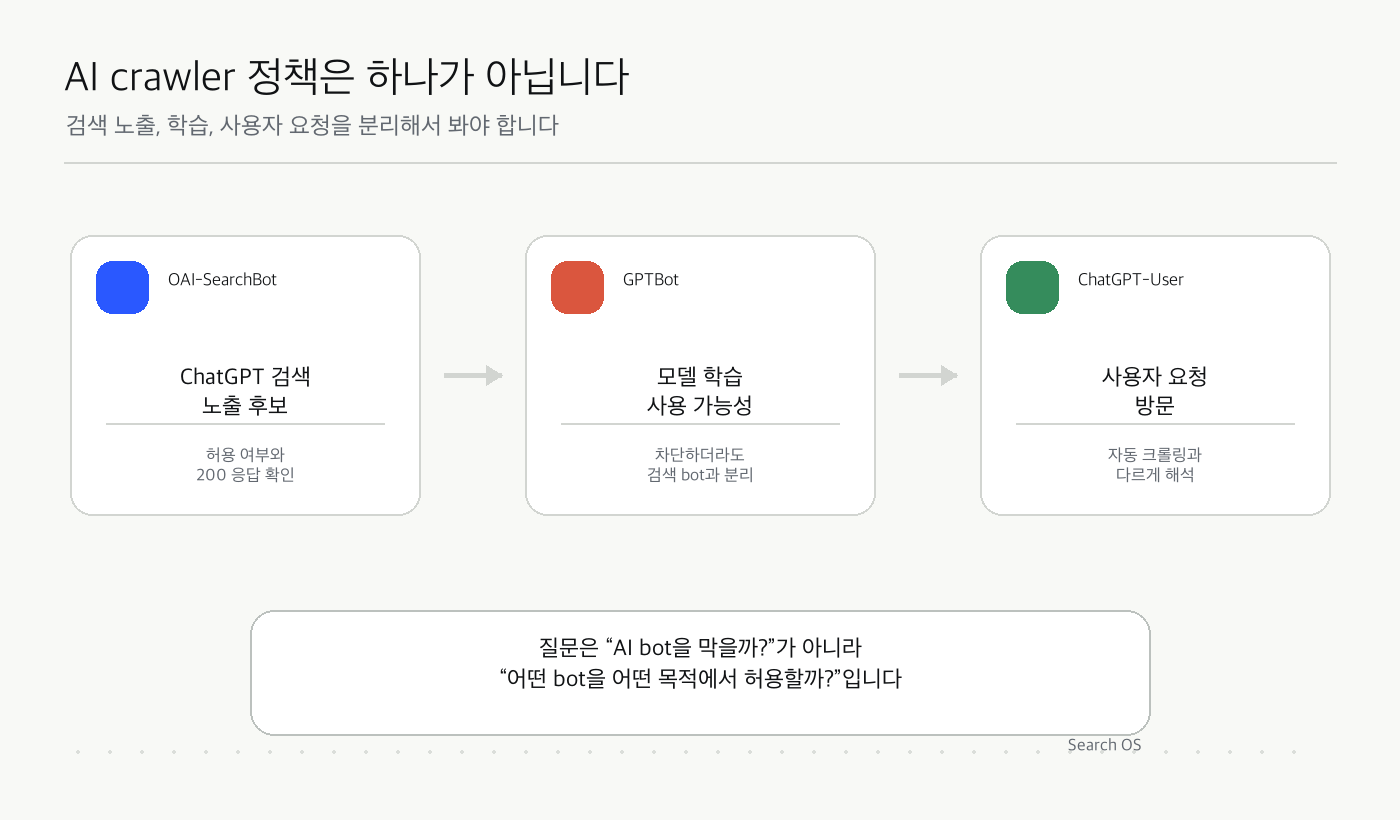
AI crawler 정책은 하나가 아닙니다
검색 노출, 학습, 사용자 요청을 분리해서 봐야 합니다
| label | title | subtitle | note |
|---|---|---|---|
| OAI-SearchBot | ChatGPT 검색 노출 후보 | 허용 여부와 200 응답 확인 | |
| GPTBot | 모델 학습 사용 가능성 | 차단하더라도 검색 bot과 분리 | |
| ChatGPT-User | 사용자 요청 방문 | 자동 크롤링과 다르게 해석 |
질문은 “AI bot을 막을까?”가 아니라 “어떤 bot을 어떤 목적에서 허용할까?”입니다
Search OS
OAI-SearchBot, GPTBot, ChatGPT-User를 검색 노출, 학습, 사용자 요청으로 분리한 AI crawler 정책 지도 여기까지만 보면 정책이 단순해 보이지만, 실제 운영은 그렇지 않습니다. 현실의 사이트 운영에는 robots.txt만 있는 게 아닙니다. WAF, CDN, Cloudflare bot 설정, 서버 렌더링, CSR 렌더링, 로그인 벽, 국가별 차단, rate limit, 캐시 정책이 모두 얽혀 있습니다. 마케팅팀이 보안팀에 던질 질문도 달라집니다. "GPTBot을 막았나요?"보다 "OAI-SearchBot은 실제로 들어오고 있나요?"가 먼저입니다.
막아도 바로 사라지지 않는 이유
GPTBot을 막았는데도 ChatGPT 답변에서 브랜드가 바로 사라지지 않는 경우가 있습니다. 이상한 현상은 아닙니다. AI 검색 답변은 오늘 들어온 crawler 하나만 보고 만들어지지 않습니다. 이미 수집된 정보, 이전에 평가된 페이지, 다른 공개 출처, 검색 인덱스, 외부 리뷰, 커뮤니티, 위키, 제휴 페이지가 함께 영향을 줍니다. Search OS가 운영에서 본 흐름도 비슷했습니다. GPTBot 접근을 제한해도 기존에 노출되던 브랜드 언급은 한동안 남았습니다. 특히 브랜드명이 강하거나, 외부 출처가 많거나, 과거에 페이지가 잘 수집된 경우에는 더 오래 남았습니다. 그런데 이 상태를 "문제없다"로 해석하면 위험합니다. AI 검색은 한 번 잡힌 답변이 영구히 고정되는 구조가 아닙니다. 시간이 지나며 페이지는 다시 평가되고, 더 최신의 근거가 들어오고, 접근 가능한 출처가 바뀌고, 답변 구성도 달라집니다. 바로 사라지지 않는다는 사실은 안심할 근거가 아닙니다. 오히려 더 위험합니다. 팀이 리스크를 늦게 발견하기 때문입니다.
시간이 지나며 인용이 줄어든 이유
고객사 운영에서 변화는 대체로 이렇게 흘렀습니다. 초기에는 답변에 남아 있었습니다. 그다음에는 등장 빈도가 흔들렸습니다. 시간이 더 지나자 특정 질문군에서 인용이 줄었습니다. 이걸 "GPTBot 차단 하나 때문에 100% 발생했다"고 단정할 수는 없습니다. AI 답변은 여러 신호가 섞이기 때문입니다. 다만 Search OS가 봇로그와 인용 모니터링을 함께 봤을 때, 접근 정책과 인용 안정성 사이에는 무시하기 어려운 상관이 있었습니다.
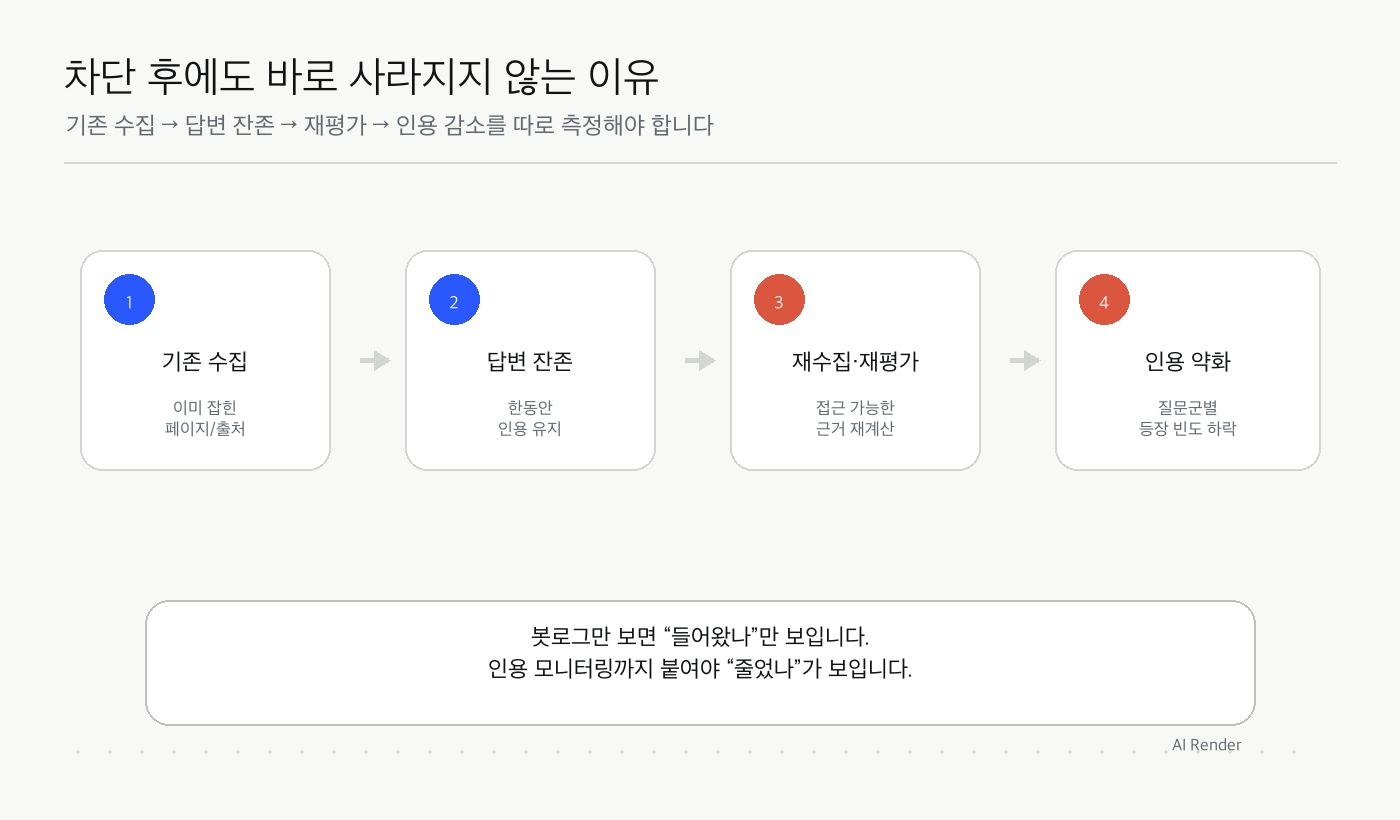
차단 후에도 바로 사라지지 않는 이유
기존 수집 → 답변 잔존 → 재평가 → 인용 감소를 따로 측정해야 합니다
| 순서 | 제목 | 설명 |
|---|---|---|
| 1 | 기존 수집 | 이미 잡힌 페이지/출처 |
| 2 | 답변 잔존 | 한동안 인용 유지 |
| 3 | 재수집·재평가 | 접근 가능한 근거 재계산 |
| 4 | 인용 약화 | 질문군별 등장 빈도 하락 |
봇로그만 보면 “들어왔냐”만 보입니다. 인용 모니터링까지 붙여야 “줄었냐”가 보입니다.
GPTBot 차단 이후 기존 인용이 즉시 사라지지 않다가 재수집과 재평가를 거치며 점차 약해지는 운영 관찰 흐름 자주 겹쳐 있던 원인은 네 가지였습니다.
원인 | 실제로 벌어지는 일 | 결과 |
|---|---|---|
Search bot까지 같이 막힘 | GPTBot만 막으려다 | ChatGPT 검색 답변에 들어갈 근거가 약해짐 |
렌더링 실패 | CSR 페이지, 자동화 페이지, 상품 상세 페이지를 bot이 제대로 읽지 못함 | 페이지는 있어도 답변 근거로 쓰기 어려워짐 |
최신성 신호 약화 | 수정된 콘텐츠가 재수집되지 않거나 sitemap/lastmod가 맞지 않음 | 오래된 외부 출처가 공식 페이지를 대체함 |
정책 변경 추적 부재 | 보안팀이 WAF/Cloudflare 정책을 바꿨지만 마케팅팀이 모름 | 인용 감소 원인을 몇 주 뒤에야 발견함 |
Search OS가 AI Render로 주로 다루는 문제도 여기에 있습니다. 많은 자동화 페이지는 사람이 브라우저로 보면 정상입니다. AI crawler가 보는 HTML은 다를 수 있습니다. 상품명, 가격, FAQ, 비교표, CTA, 지역명, 진료과, 기능 설명이 JavaScript 뒤에 있거나, 늦게 로드되거나, bot 접근에서 빠지는 경우가 있습니다. AI Render는 이 문제를 줄이기 위해 들어가는 운영 레이어입니다. bot이 실제로 읽어야 하는 핵심 정보를 안정적으로 제공하고, 페이지별 메타데이터와 구조화 데이터를 맞추고, 어떤 crawler가 어떤 응답을 받았는지 로그로 확인합니다. AI 검색에서 "좋은 글"만으로 부족한 이유가 여기에 있습니다. crawler가 읽지 못하면 좋은 글도 근거가 되기 어렵습니다.
GPTBot 차단 정책은 이렇게 나눠야 합니다
마케팅팀이 보안팀에 요청할 때 가장 피해야 하는 말이 있습니다. "AI bot 다 막아주세요."이렇게 요청하면 검색 노출, 학습 차단, 사용자 요청, 광고 검증, 보안 bot 대응이 한꺼번에 섞입니다. 요청은 crawler별 정책으로 나눠야 합니다.
의사결정 | 권장 접근 |
|---|---|
ChatGPT 검색 답변에 나오고 싶다 |
|
학습 사용은 제한하고 싶다 |
|
사용자가 ChatGPT에서 직접 링크를 열 때는 허용하고 싶다 |
|
Google 검색 노출은 유지하고 싶다 |
|
AI crawler 비용과 서버 부하가 걱정된다 | Cloudflare/WAF에서 allow/block/rate limit을 crawler별로 나눔 |
자동화 페이지가 많다 | AI Render, sitemap, metadata, JSON-LD, 봇로그를 함께 운영 |
Google 쪽도 같은 원리입니다. Google-Extended는 Google Search의 일반 ranking signal과 다르게 봐야 합니다. Google은 Google-Extended가 Google Search 포함 여부나 랭킹 신호에 영향을 주지 않는다고 설명합니다. 이 역시 "그래서 아무렇게나 막아도 된다"는 뜻은 아닙니다. Gemini, grounding, Search, 일반 Googlebot이 섞이면 팀이 원인을 추적하기 어려워집니다. AI crawler 정책은 보안 설정이면서 동시에 마케팅 설정입니다. 검색팀, 보안팀, 개발팀이 같은 표를 봐야 하는 이유입니다.
마케터가 이번 주에 확인할 것
GPTBot을 막을지 말지는 회사마다 다릅니다. 콘텐츠 비즈니스, 폐쇄형 리서치, 유료 데이터, 병원/금융/법률처럼 민감한 업종은 더 조심해야 합니다. 반대로 AI 검색에서 브랜드 발견성이 중요한 B2B SaaS, 이커머스, 로컬 서비스, 대규모 플랫폼은 검색 bot 차단이 곧 기회 손실이 될 수 있습니다. 결정 전에 아래 7가지를 확인하세요.
robots.txt에OAI-SearchBot,GPTBot,ChatGPT-User,Google-Extended정책이 따로 적혀 있는가WAF나 Cloudflare에서 user-agent 또는 IP range 기준으로 추가 차단이 걸려 있는가
실제 봇로그에서
OAI-SearchBot이 200 응답을 받고 있는가중요한 자동화 페이지가 bot 요청에서 정상 HTML을 반환하는가
sitemap.xml, lastmod, canonical이 최신 페이지와 맞는가
ChatGPT, Perplexity, Gemini에서 핵심 질문군별 인용 변화를 주 단위로 보고 있는가
차단 정책 변경 전후의 인용 횟수와 AI referral 변화를 기록하고 있는가
이 체크리스트를 통과하지 못했다면, "GPTBot을 막아도 되나요?"라는 질문에 답하기 어렵습니다. 정책은 맞을 수 있습니다. 운영이 틀릴 수 있습니다.
Search OS는 이 문제를 어떻게 봅니다
Search OS는 이 문제를 "GPTBot을 막을까 말까"라는 단일 설정으로 보면 안 됩니다. 실제 고객사에서 더 자주 보이는 문제는 설정값 하나보다 운영 단절입니다. 마케팅팀은 ChatGPT 답변에서 브랜드가 어떻게 보이는지 확인합니다. 보안팀은 크롤링 부하와 학습 사용 리스크를 봅니다. 개발팀은 렌더링, sitemap, robots.txt, canonical 같은 파일과 응답 상태를 봅니다. 각 팀의 판단은 모두 필요합니다. 리스크는 그 판단이 서로 이어지지 않을 때 커집니다. 예를 들어 보안팀은 학습 차단을 위해 GPTBot만 막았다고 생각했는데 실제로는 OAI-SearchBot까지 403을 받고 있을 수 있습니다. 반대로 search bot은 200 응답을 받지만 자동화 페이지의 핵심 정보가 JavaScript 뒤에 숨어 있어 AI가 읽을 만한 HTML을 받지 못하는 경우도 있습니다. 둘 다 마케팅팀 입장에서는 "AI 검색에서 약해지는" 문제로 보입니다. Search OS는 먼저 세 가지를 한 흐름으로 묶어 봅니다.
어떤 crawler가 어떤 페이지군에 들어왔는가
그 crawler가 어떤 HTML, metadata, JSON-LD, canonical, sitemap 신호를 받았는가
정책 변경 전후로 인용 안정성, AI referral, GSC, GA4 지표가 어떻게 흔들렸는가
AI Render는 여기서 콘텐츠를 더 쓰는 도구가 아닙니다. AI crawler가 실제로 읽어야 할 정보를 안정적으로 받게 만드는 운영 레이어입니다. 자동화 페이지가 많은 사이트일수록 이 차이가 커집니다. 사람 눈에는 정상인 페이지라도 crawler가 받는 응답은 비어 있거나, 오래됐거나, 대표 URL과 어긋나 있을 수 있기 때문입니다. 결국 이 작업은 "AI 검색용 글을 더 쓰자"가 아닙니다. 무엇을 열고, 무엇을 막고, 무엇을 읽히게 만들고, 그 결과가 답변에서 어떻게 바뀌는지 확인하는 일입니다.
GPTBot 차단은 SEO 설정이 아니라 AI 검색 거버넌스입니다
GPTBot을 막는다고 ChatGPT 검색에서 바로 사라지지는 않습니다. 바로 사라지지 않는다는 말이 안전하다는 뜻은 아닙니다. Search OS가 실제 고객사에서 본 패턴은, 차단 후에도 한동안 남아 있던 인용이 시간이 지나며 약해지는 흐름이었습니다. crawler를 다시 나눠 봐야 합니다. GPTBot은 학습 사용과 관련해 봅니다. OAI-SearchBot은 ChatGPT 검색 노출과 연결해 봐야 합니다. ChatGPT-User는 사용자 요청 흐름으로 따로 봅니다. Google 쪽도 Googlebot과 Google-Extended를 분리해야 합니다. AI 검색 시대의 crawler 정책은 보안팀만의 설정이 아닙니다. 마케팅팀이 검색 노출을 잃지 않으려면, 이제 robots.txt와 WAF 정책을 봐야 합니다. 보안팀이 콘텐츠 보호를 하려면, 어떤 차단이 검색 가시성에 영향을 주는지도 알아야 합니다. 막는 선택이 맞을 때도 있습니다. 무엇을 막았는지 모르는 상태가 가장 위험합니다.